
Reconsidérer la façon dont nous mesurons les forêts avec le LiDAR – Methods Blog

Message fourni par Jeff W.Atkins (il/elle)
Les chercheurs en écologie ont adopté la détection et la télémétrie de la lumière (LiDAR) comme moyen de quantifier la structure de l’écosystème au cours des 25 dernières années. Cela est particulièrement vrai dans la recherche liée aux forêts, car le LiDAR permet d’estimer la structure de l’écosystème avec des détails incroyablement fins, sur de vastes zones. LiDAR peut fonctionner à l’échelle d’arbres individuels, par exemple algorithmes de délimitation de couronne qui identifient les couverts d’arbres singuliers – ou le niveau du peuplement avec mesures structurelles agrégées. Dans cet article de blog, Jeff partage un aperçu de lui et de la récente publication de son co-auteur « Dépendance à l’échelle de LiDAR-diversité structurale forestière dérivée», qui propose que l’utilisation de LiDAR nécessite une réévaluation statistique pour s’assurer que nous mesurons ce que nous pensons être.
Qu’est-ce que LiDAR ?
LiDAR est une forme de télédétection active basée sur l’idée que la vitesse de la lumière étant constante, nous pouvons mesurer des distances en faisant rebondir la lumière sur des objets et en mesurant le temps nécessaire au retour du signal.
LiDAR fournit des estimations précises et exactes de la hauteur de la forêt ainsi que la possibilité de créer des mesures agrégées dérivées qui décrivent des dimensions supplémentaires de la structure forestière, telles que la complexité de la canopée, la disposition, l’ouverture, la variabilité et la position. Ces mesures agrégées sont puissantes car elles déplacent le concept de structure forestière au-delà des arbres isolés et individuels, vers la compréhension de la structure forestière et de la complexité structurelle en tant que propriété émergente en soi.
Le LiDAR comme outil
Dans mon recherche postdoctoralej’ai consacré beaucoup de temps à créer outils qui calculent ces métriques, tout en explorant également comment ces métriques expliquaient les relations observées. Ceci comprend comment les forêts plus complexes utilisent la lumière plus efficacement ou comment différent les perturbations forestières créent différentes signatures structurelles. Au-delà de mon propre travail, d’autres ont utilisé des métriques structurelles LiDAR pour explorer les relations entre la structure forestière et une myriade de sujets, y compris, mais sans s’y limiter, la diversité des espèces, microclimats, réponse de la forêt au changement climatiqueet productivité.

Je me suis trouvé de plus en plus curieux de savoir comment la structure forestière, telle qu’elle est déduite à l’aide du LiDAR, évolue. Plus simplement, pensons à la hauteur de la forêt. LiDAR est différent de nombreuses autres formes de télédétection en ce qu’il n’a pas d’échelle native. Les données brutes se présentent sous la forme de nuages de points, d’estimations individuelles de la hauteur ou de la distance à des points discrets.
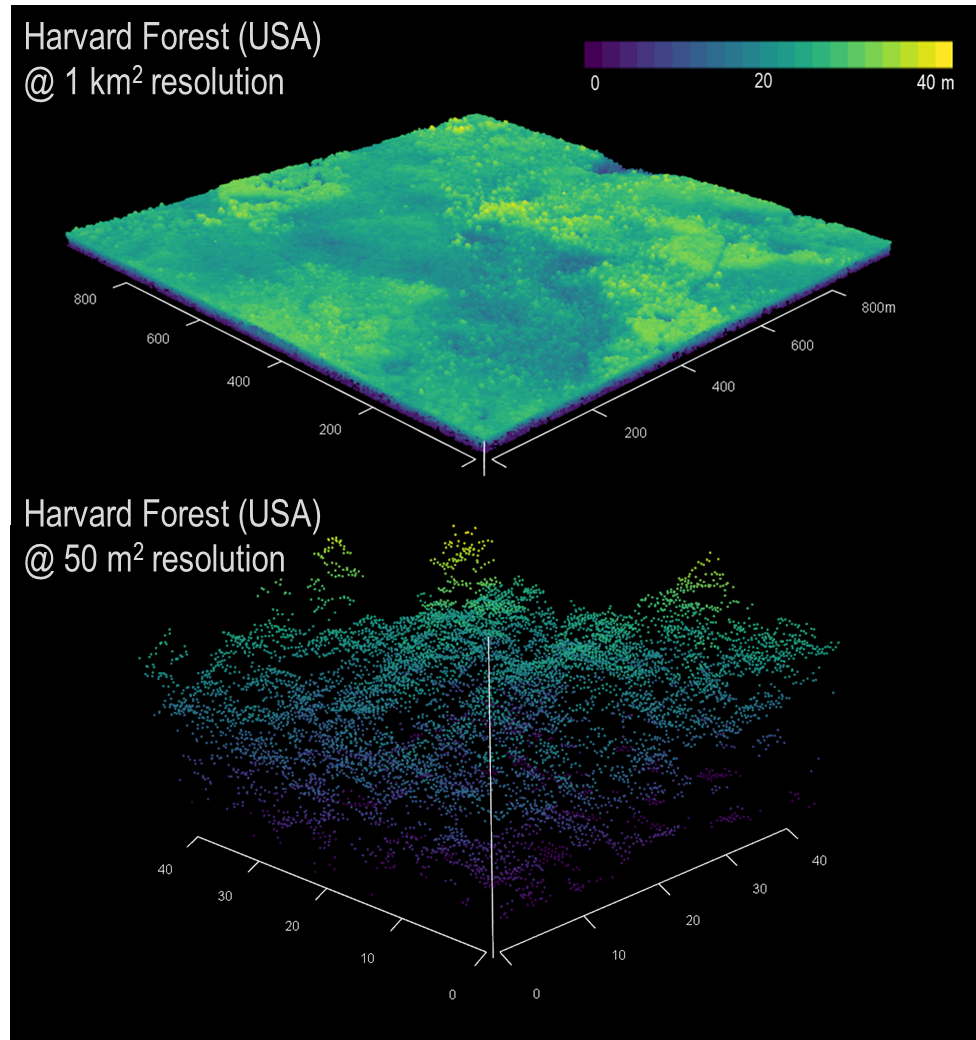
Comparez cela à l’imagerie satellite (par exemple, Landsat), qui se présente sous la forme de pixels quadrillés de taille uniforme. L’imagerie Landsat se présente généralement sous la forme d’une trame de données, 1 km2 dans la zone avec chaque pixel ayant une résolution native de 30 m – chaque pixel est une donnée de 30 x 30 m.
Les nuages de points LiDAR contiennent souvent des millions de points, chacun avec une valeur x, y, z. X et y étant la position au sol et z étant la position au-dessus de ce point x, y. Alors déjà, on ajoute une autre dimension. Pour chaque mètre carré au sol, il peut y avoir entre 2-3 points et jusqu’à 12-15 points. Bien que nous nous concentrions sur le LiDAR aérien, qui est collecté à partir d’aéronefs, le LiDAR peut également être collecté à partir de véhicules aériens inoccupés (UAV), de scanners au sol (LiDAR terrestre ou TLS) ou de satellites spatiaux (par exemple, GEDI, ICESat-2) .
Défis liés à LiDAR
Sous cette forme brute, les données LiDAR sont quelque peu intimidantes, ce qui nécessite de les simplifier dans un format plus utile. Les données les plus utilisées produites par LiDAR sont les modèles de hauteur de canopée (CHM). Celles-ci, comme les données Landsat, sont des tuiles raster de hauteur de forêt. Mais c’est là que réside le nœud du problème : à quelle résolution agrège-t-on ces retours de points LiDAR pour donner un modèle de hauteur utile et représentatif ?
L’approche standard n’a pas été de considérer directement les données LiDAR. Il s’agit plutôt d’utiliser la résolution d’intérêt pour tout problème à résoudre, ou d’agréger les données LiDAR à la même résolution d’un autre produit de données utilisé dans l’analyse.
Cette approche plutôt arbitraire en est une qui m’a longtemps vexé. Comment savons-nous quelle est la résolution « appropriée » à utiliser ? Que pouvons-nous faire pour appliquer une mesure (sans jeu de mots) de rigueur statistique à la manière dont nous agrégeons les données lidar pour les applications et la recherche ?
Une solution possible empruntée à l’hydrologie, et celle que nous explorons dans notre manuscrit, est la zone élémentaire représentative (REA). Comme Bloschl et al. (1995) écrit dans Hydrological Processes,
» [REA] . . . promet une échelle spatiale sur laquelle les représentations des processus peuvent rester simples et à laquelle le comportement distribué des bassins versants peut être représenté sans la complexité apparemment indéfinissable de l’hétérogénéité locale.
Nous pouvons considérer la REA comme l’échelle spatiale sur laquelle un processus est mesurable et statistiquement stable, nous permettant ainsi de faire des inférences plus rigoureuses.
Création d’une échelle standard
Pour appliquer le concept REA au LiDAR, nous devions d’abord trouver un moyen statistique d’identifier le REA. Nous avons choisi d’utiliser l’analyse des points de changement, une méthode statistique qui identifie le moment où la distribution de probabilité d’un processus stochastique ou d’une série chronologique change de manière significative.
Avec les données spatiales, des approches telles que la régression segmentée sont utilisées. Dans la régression segmentée, la plage d’une variable indépendante est divisée en intervalles avec des lignes ajustées à ces intervalles. Ensuite, les pentes de ces lignes sont testées pour voir si elles diffèrent de manière significative. Si une différence est identifiée entre les pentes, cela indique un changement dans la relation entre la variable indépendante et dépendante. Notre analyse a utilisé la résolution d’agrégation comme variable indépendante.
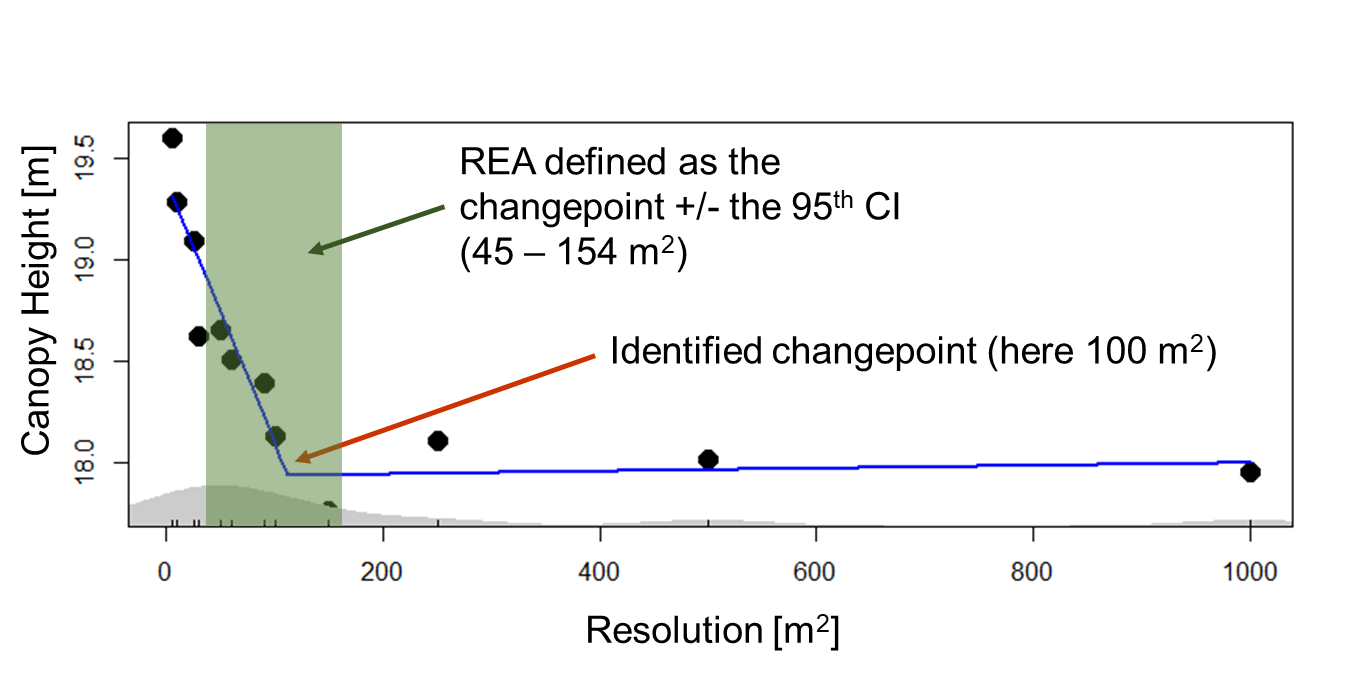
À partir d’une analyse segmentée, nous trouvons le point auquel ces pentes diffèrent, connu sous le nom de « point de rupture ». En utilisant ce point de changement avec les intervalles de confiance associés, nous pouvons identifier le REA pour chaque métrique structurelle LiDAR.
Dans l’exemple ci-dessus, nous examinons la hauteur du couvert forestier. Cela a été mesuré comme la hauteur moyenne de la canopée extérieure pour la forêt de Harvard (États-Unis) par rapport à l’échelle de résolution ou à la taille de grain à laquelle les valeurs de hauteur de la canopée sont agrégées. Le point de changement, à 100 m, représente la moyenne de la hauteur de retour LiDAR la plus élevée pour chaque 1 m2 dans un grain spatial défini de 100 m (~1000 mesures).
La ligne bleue montre la régression segmentée ajustée. Dans cet exemple, les résolutions spatiales en dehors des limites supérieure et inférieure du REA (en vert, ci-dessus), ne sont pas représentatives du peuplement forestier. À des résolutions spatiales inférieures, nous observons des variations intra-canopée à partir d’arbres individuels. Au-dessus de 154 m, on assiste à l’influence du paysage : évolution des sols, des reliefs ou encore du climat.
Si nous devions effectuer une analyse à Harvard Forest pour relier la structure forestière à une réponse fonctionnelle (par exemple, la productivité aérienne, l’efficacité de l’utilisation de la lumière), agréger les estimations de hauteur à une résolution spatiale entre 45 et 154 m2, basé sur notre analyse REA, fournirait un degré élevé de confiance que nous représentons suffisamment la hauteur de la forêt. Cette ERIE pourrait être utilisée avec un haut degré de confiance avec n’importe quelle autre forêt tempérée d’âge et de composition similaires.
L’avenir du LiDAR
Nous abordons également d’autres mesures de la structure forestière, y compris la couverture de la canopée et des mesures dérivées d’ordre supérieur telles que la rugosité, la diversité de la hauteur foliaire et le rapport de relief de la canopée, des mesures qui décrivent la complexité structurelle des forêts. Nous constatons des différences dans l’ERIE lorsque nous considérons le type de forêt (par exemple, à feuilles larges, à feuilles d’aiguilles).
Le REA pour certaines mesures de hauteur est plus faible pour les forêts de feuilles d’aiguilles, probablement en raison de ces forêts qui ont tendance à être plus équiennes, plus uniformes que les forêts de feuillus utilisées dans cette étude. En outre, le REA pour la couverture de la canopée est plus élevé dans les forêts de feuilles d’aiguilles, ce qui pourrait être fonction de l’architecture individuelle des feuilles par rapport aux aiguilles.

De plus, l’application de méthodologies et de cadres d’autres domaines pourrait grandement éclairer la façon dont nous travaillons avec LiDAR non seulement dans les forêts, mais dans tous les écosystèmes. Il y a aussi une question ouverte concernant le rôle de l’âge de la forêt, car nous savons que la structure de la forêt change avec l’âge. Encore une fois, cela dépend du système, car toutes les forêts ne présentent pas une relation âge-structure similaire.
Nous espérons que le concept REA sera utile aux lecteurs de MEE et à ceux qui travaillent avec LiDAR. La capacité de caractériser la structure forestière comme une propriété émergente a de nombreuses utilisations profondes dans la recherche écologique et nous sommes enthousiasmés par l’avenir.
Lisez entièrement l’article:
« Dépendance à l’échelle de la diversité structurelle des forêts dérivée du LiDAR”