
Complexité croissante dans la modélisation de la répartition des espèces – Blog des méthodes
Megan Laxton et ses collègues avaient initialement décidé de traduire un exemple existant de modèle de répartition des espèces dans un nouveau cadre logiciel. Cependant, ce qui était à l’origine un simple exemple de modélisation s’est transformé en une discussion sur la complexité structurelle des modèles de distribution des espèces.
Complexité des modèles de distribution des espèces
L’idée originale de notre article était de fournir un exemple concret démontrant l’utilisation du package R. je travaille pour adapter un modèle de processus de points marqués aux données de distribution des espèces. Un modèle de processus ponctuel marqué est utilisé pour modéliser la distribution spatiale (ou spatio-temporelle) des événements et leurs caractéristiques associées.
je travaille est un wrapper convivial et une extension du package existant INLA, qui peut s’adapter à un large éventail de modèles statistiques complexes et est – en raison de son efficacité de calcul et de sa flexibilité – particulièrement adapté à l’ajustement de modèles spatiaux et spatio-temporels complexes. Le package a été développé à l’origine en gardant à l’esprit les ensembles de données complexes et les processus d’observation que l’on trouve couramment dans les applications écologiques. Il existe donc une volonté de fournir des exemples écologiques appliqués du logiciel en action.
Cependant, comme c’est si souvent le cas dans la recherche, ce qui devait être un simple exemple de modèle appliqué s’est transformé en un problème bien plus complexe. Les méthodes prédictives et de visualisation de je travaille a mis en évidence des caractéristiques inhabituelles des prédictions du modèle, incitant à une enquête plus approfondie sur la structure du modèle. Cela a conduit à l’élaboration d’un article qui analyse quatre modèles successivement plus complexes, posant la question : quand une complexité accrue est-elle bénéfique, et quand ne l’est-elle pas ?
Habitat inégal
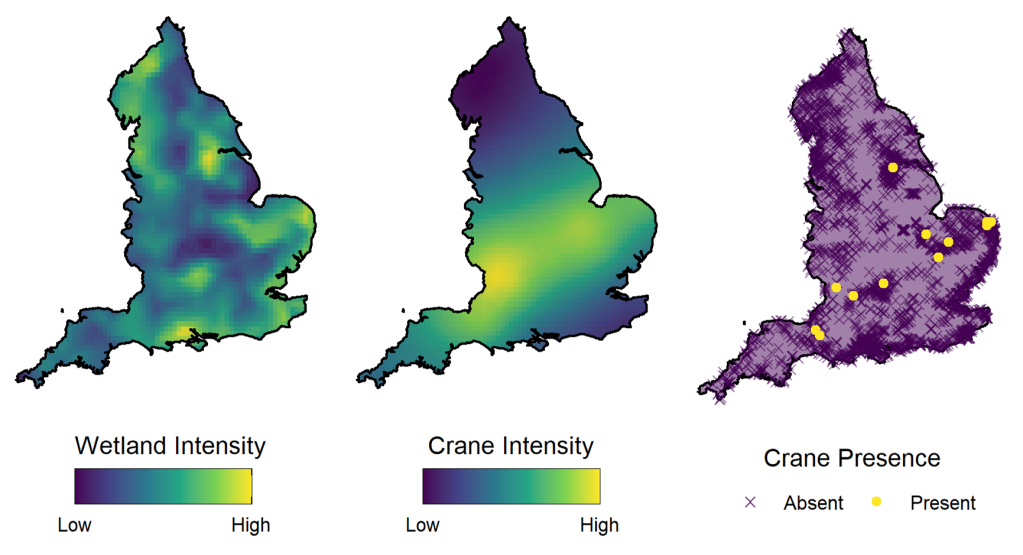
Notre exemple regarde la répartition des grues eurasiennes (gravier gravier) au Royaume-Uni. Les nids des couples reproducteurs de grues ne se trouvent que dans les habitats de zones humides, de sorte que les zones humides peuvent être considérées comme des « parcelles d’habitat » pour cette espèce – des zones d’habitat convenable divisées par des zones interstitielles aux conditions inappropriées.
Les parcelles d’habitat influencent la répartition des espèces en créant une restriction sur les emplacements spatiaux où les espèces peuvent être trouvées, divisant ainsi la zone d’étude. À plus grande échelle, la densité de ces parcelles peut également influencer la répartition d’une population en tenant compte des zones générales jugées préférables en contenant des densités plus élevées d’habitats convenables.
Dans notre article, nous utilisons la modélisation de processus par points marqués pour modéliser à la fois la répartition des zones humides et la répartition des grues dans un modèle conjoint. Nous utilisons des effets aléatoires distincts pour tenir compte des structures spatiales des zones humides et des grues. Cela nous permet à la fois de prendre en compte les restrictions sur la répartition spatiale de l’habitat et de voir la connectivité spatiale de la population qui est indépendante de la répartition des parcelles d’habitat sous-jacentes.
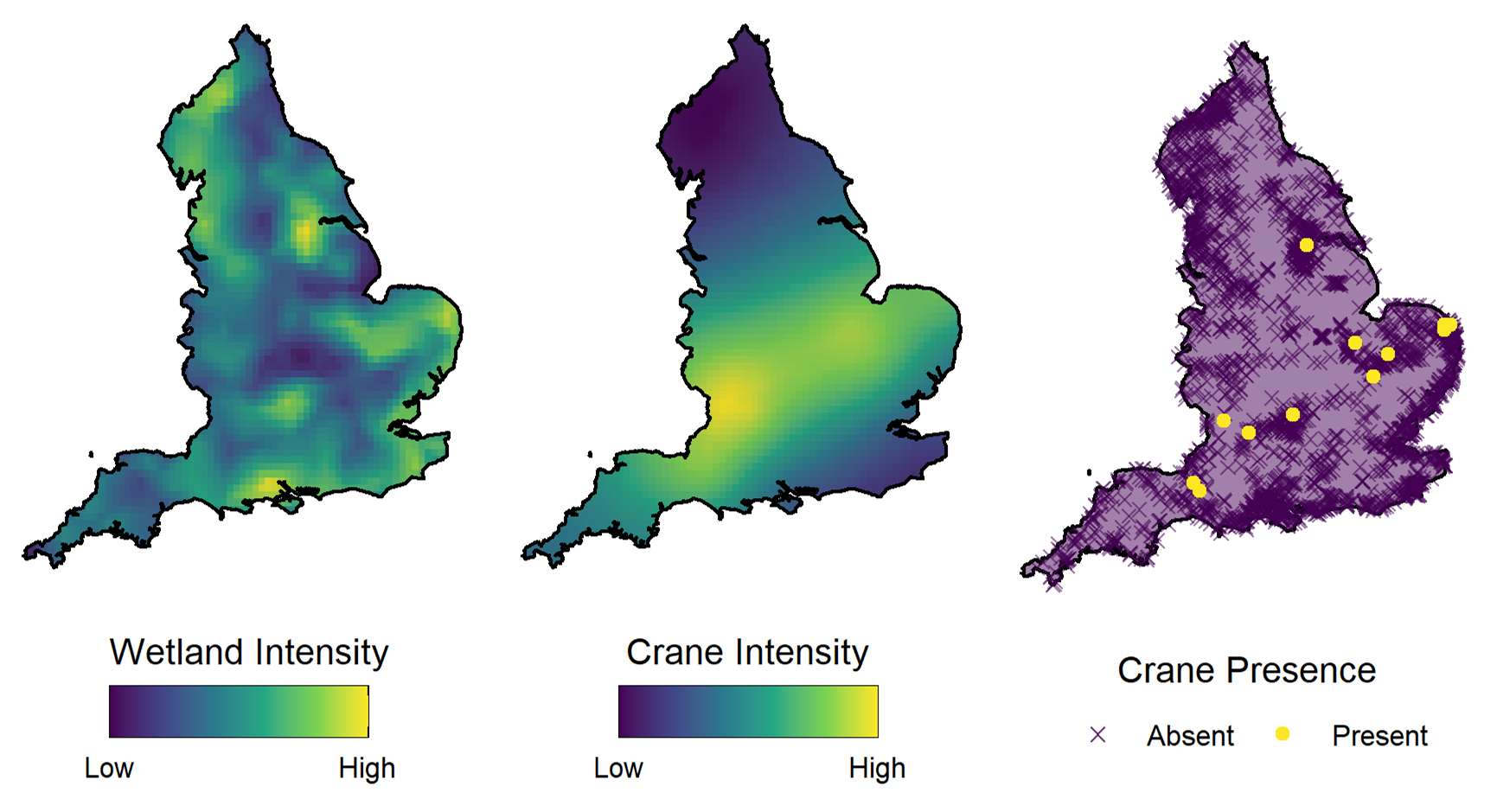
La mise en place du modèle dans ce cadre et l’inclusion de ces effets spatiaux est un exemple de complexité structurelle dans un modèle fondé sur le réalisme écologique et améliore l’interprétabilité du modèle. Cependant, toutes les complexités des modèles ne permettent pas une telle amélioration.
Réintroductions et invasions
Nous sommes souvent intéressés à modéliser la répartition des espèces récemment (ré)introduites dans un environnement, pour estimer comment la population pourrait se propager. C’est le cas dans notre exemple de grue ; l’espèce a été historiquement disparue et récemment réintroduite au Royaume-Uni.
Les données utilisées dans l’exemple sont caractéristiques du type de données collectées au début d’une (ré)introduction ; contenant peu de présences observées de l’espèce, qui sont regroupées étroitement dans l’espace. Cela signifiait que nos observations de la répartition spatiale globale de l’espèce différaient très peu d’une année à l’autre, créant un problème lors de l’inclusion d’un effet de corrélation temporelle dans le modèle.
Le modèle le plus complexe considéré dans notre étude a en réalité produit des prédictions inexactes et trompeuses. Il s’agit d’un exemple de cas dans lequel les données peuvent être insuffisantes pour prendre en charge certains composants du modèle, de sorte que l’ajout de complexité inhibe en réalité les objectifs de l’étude.
La complexité pour la complexité ?
L’inclusion de composants de modèle complexes peut nous permettre de mieux représenter la dynamique des populations et les préférences en matière d’habitat dans les modèles de répartition des espèces, améliorant ainsi la précision prédictive tout en maintenant l’interprétabilité des résultats. Cependant, la relation entre la complexité du modèle et la compréhension écologique n’est pas linéaire ; L’inclusion de certains composants complexes du modèle peut conduire à des prédictions inexactes si nous ne sommes pas vigilants. La complexité croissante des modèles nécessite un examen attentif du rôle de chaque composant du modèle, de la manière dont il est pris en charge par les données et de l’impact de son inclusion sur les résultats et les prévisions du modèle.
Vous pouvez lire l’article complet ici