
Combler le fossé entre le passé ancien et l’avenir numérique – Blog des méthodes

Article fourni par Margot Belot
Si vous m’aviez demandé il y a quelques années ce que je ferais aujourd’hui, je vous aurais probablement répondu que je déterrerais des objets anciens quelque part ou que je les cataloguerais dans un musée. J’ai une formation en archéologie et en histoire de l’art ; pendant longtemps, mon monde tournait autour de la nature tactile des objets physiques, manipulant, décrivant et assurant leur préservation avec soin.
Dans une vie professionnelle antérieure, j’ai travaillé comme médiateur culturel et chercheur invité, souvent retrouvé au fond des archives pour déchiffrer l’écriture manuscrite historique. Je me souviens très bien de mes efforts à travers des documents écrits en Sütterlin, une vieille écriture allemande, essayant d’extraire un sens des boucles et des gribouillages de conservateurs morts depuis longtemps pour comprendre la provenance des échinoïdes fossiles. Même si j’adorais le « travail de détective », je ressentais le poids croissant d’une crise silencieuse : le volume considérable de l’histoire qui restait non documenté et, par conséquent, inaccessible au monde.
Aujourd’hui, cependant, je passe moins de temps avec des truelles et des pinceaux et plus de temps à lutter avec le code Python et les réseaux de neurones convolutifs. Ce changement n’était pas une rupture avec mon amour de l’histoire, mais une évolution moderne de celle-ci. Ma curiosité pour l’utilisation des outils numériques pour mieux comprendre les documents anciens m’a conduit à mon rôle actuel de gestionnaire de données au Museum für Naturkunde Berlin (MfN).
Une nouvelle boîte à outils pour les vieux problèmes
Le cheminement vers ce travail n’a pas été une ligne droite. Alors que je travaillais comme spécialiste de la numérisation au MfN, j’ai pu constater l’ampleur du défi. Nous avons des millions de spécimens d’insectes, chacun portant une petite étiquette fragile épinglée en dessous contenant des données vitales : où il a été trouvé, quand et par qui. Pour accéder à ces données à grande échelle, j’ai réalisé que j’avais besoin d’une boîte à outils qui n’existait pas dans le répertoire d’un archéologue traditionnel.
En 2021, j’ai franchi le pas et me suis inscrit à une formation Data Science. Ce fut une immersion intense dans un monde apparemment très éloigné de l’archéologie : les algorithmes, l’apprentissage automatique et le traitement du langage naturel. Pourtant, j’ai vite commencé à voir des liens. Les techniques de vision par ordinateur utilisées pour la reconnaissance de texte moderne pourraient constituer la « truelle numérique » nécessaire pour extraire les données de ces minuscules étiquettes de musée. Les graines de ce qui allait devenir ELIE ont été plantées lors de mon dernier projet de synthèse : Reconnaissance de textes manuscrits et apprentissage automatique appliqués à la numérisation des étiquettes de spécimens dans les collections d’histoire naturelle.
Le défi « Image »
Le moment n’aurait pas pu être mieux choisi. Le MfN avait lancé une initiative de numérisation massive en utilisant un système de tapis roulant à grande vitesse développé par la société néerlandaise Picturae. Entre 2022 et 2023 seulement, le musée a numérisé 650 000 spécimens grâce à ce système.
Soudain, nos serveurs ont été inondés de dizaines de milliers d’images par mois. Même si les images étaient superbes, elles ont créé un nouveau problème. Nous avions les images, mais les données sur les étiquettes étaient piégées en pixels.
Dans le monde des musées, nous savons que plus de 85 % des métadonnées des spécimens résident sur ces étiquettes physiques ou ces registres. Taper manuellement le texte d’un demi-milliard d’insectes dans le monde prendrait des siècles. Nous avions besoin d’un moyen d’automatiser la lecture de ces étiquettes sans sacrifier la précision exigée par les taxonomistes.

Entre ÉLIE.
C’est là qu’intervient ELIE. Dans notre Méthodes en écologie et évolution article, Extraction d’informations à haut débit d’étiquettes d’échantillons imprimées à partir de la numérisation à grande échelle de collections entomologiques à l’aide d’un pipeline semi-automatisénous présentons ce pipeline comme une solution modulaire conçue spécifiquement pour les collections entomologiques.
Nous avons construit ELIE pour qu’il pense comme un conservateur. Premièrement, cela sépare les choses faciles des choses difficiles. Il utilise un réseau neuronal convolutif pour faire la distinction entre les étiquettes imprimées (que les ordinateurs lisent bien) et les étiquettes manuscrites (qui sont notoirement difficiles). Cette séparation est cruciale car, même si la reconnaissance optique de caractères (OCR) est puissante, elle reste confrontée à l’écriture manuscrite variable et cursive que l’on retrouve souvent dans les collections historiques.
Pour les étiquettes imprimées, nous avons constaté que les outils OCR modernes comme l’API Google Vision étaient incroyablement robustes, surpassant de loin les anciennes alternatives open source comme Tesseract sur nos ensembles de données.
Mais nous ne nous sommes pas contentés de lire le texte. L’une des fonctionnalités les plus intéressantes, développée par mon collègue Joël Tuberosa, est un algorithme de clustering. Étant donné que les entomologistes collectent souvent de nombreux spécimens au même endroit et au même moment (un « événement de rassemblement »), de nombreuses étiquettes sont identiques. Cela n’a aucun sens de saisir 50 fois les données de localisation « Amazonas, Brésil, 1998 ». ELIE regroupe ces étiquettes identiques afin qu’un humain n’ait qu’à en vérifier une ou deux pour valider l’ensemble du lot.
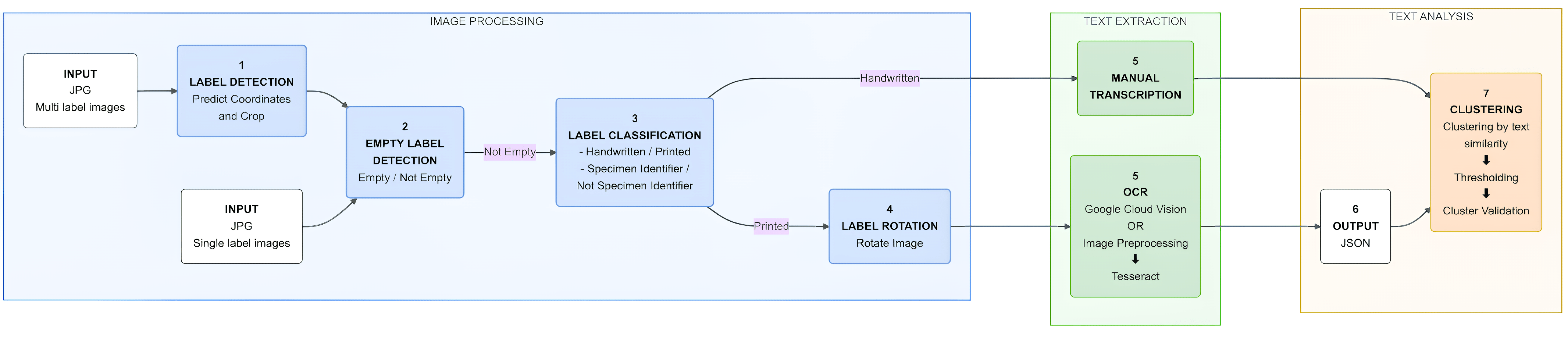
Ce que nous avons trouvé
Lorsque nous avons testé ELIE sur des ensembles de données du MfN, du Smithsonian et du Museum of Comparative Zoology de Harvard, nous avons constaté qu’il pouvait réduire l’effort de transcription manuelle jusqu’à 87 %.
Sur les étiquettes imprimées, le pipeline a atteint une précision de 98 % en matière d’extraction et de regroupement. Cela signifie que pour la grande majorité de nos collections modernes, l’ordinateur fait le gros du travail. En automatisant le travail « ennuyeux » de transcription des étiquettes imprimées, nous permettons aux chercheurs et aux conservateurs de se concentrer sur des tâches de grande valeur.

Regarder vers l’avenir
Bien entendu, le travail n’est pas terminé. La « baleine blanche » de la numérisation reste les étiquettes manuscrites, en particulier celles provenant de collections historiques, à l’encre passée et aux gribouillages idiosyncratiques. Mon expérience du déchiffrement de Sütterlin dans les archives me dit que ce ne sera pas facile !
Pour l’instant, ELIE trie ces étiquettes manuscrites pour les examiner manuellement, mais nous envisageons déjà la prochaine frontière. Nous prévoyons d’intégrer des modèles spécifiques de reconnaissance de textes manuscrits et même des grands modèles linguistiques (LLM) pour aider à interpréter ces énigmes historiques. Les LLM pourraient nous aider non seulement à lire le texte, mais aussi à le comprendre, en reliant les noms de localités abrégés à leurs coordonnées géographiques modernes ou en résolvant des synonymes taxonomiques obsolètes.
Ce projet est un merveilleux exemple de la manière dont les compétences interdisciplinaires, combinant les connaissances traditionnelles des musées avec la science moderne des données, peuvent révéler l’histoire cachée dans nos collections. Il s’avère que le passage entre l’exhumation du passé et le codage du futur n’est pas aussi large que je le pensais.
Lire l’article complet ici.