
Ce n’est qu’en comprenant ce qui cause le biais d’échantillonnage que nous pouvons le corriger – Blog Méthodes

Post fourni par Rob J. Boyd
Collègues et moi avons récemment publié un article dans Moiet son titre pourrait induire un peu de grattage de tête: «Utilisation de diagrammes causaux… pour corriger les biais d’échantillonnage géographique dans les données de surveillance de la biodiversité»(Boyd et al., 2025). Si vous connaissez l’inférence causale, vous vous demandez peut-être: «Qu’est-ce que les diagrammes causaux ont à voir avec les biais d’échantillonnage?» Et si vous êtes nouveau dans le concept, le titre n’a probablement pas beaucoup de sens. Laissez-moi expliquer…
La plupart des gens comprennent le mot «biais» pour impliquer l’injustice, les préjugés ou le favoritisme. En tant que fan du Newcastle United Football Club, je me retrouve à accuser des arbitres de biais de Premier League chaque fois que les choses ne se passent pas dans notre sens. Mais il y a bien sûr des cas de biais plus graves (et authentiques) – disons, lorsque les modèles de grandes langues prolifèrent les points de vue des humains étranges (occidentaux, éduqués, industrialisés, riches et démocratiques), car ces humains ont contribué de manière disproportionnée à la littérature publiée sur que les modèles ont été formés (Abdurahman et al., 2024).
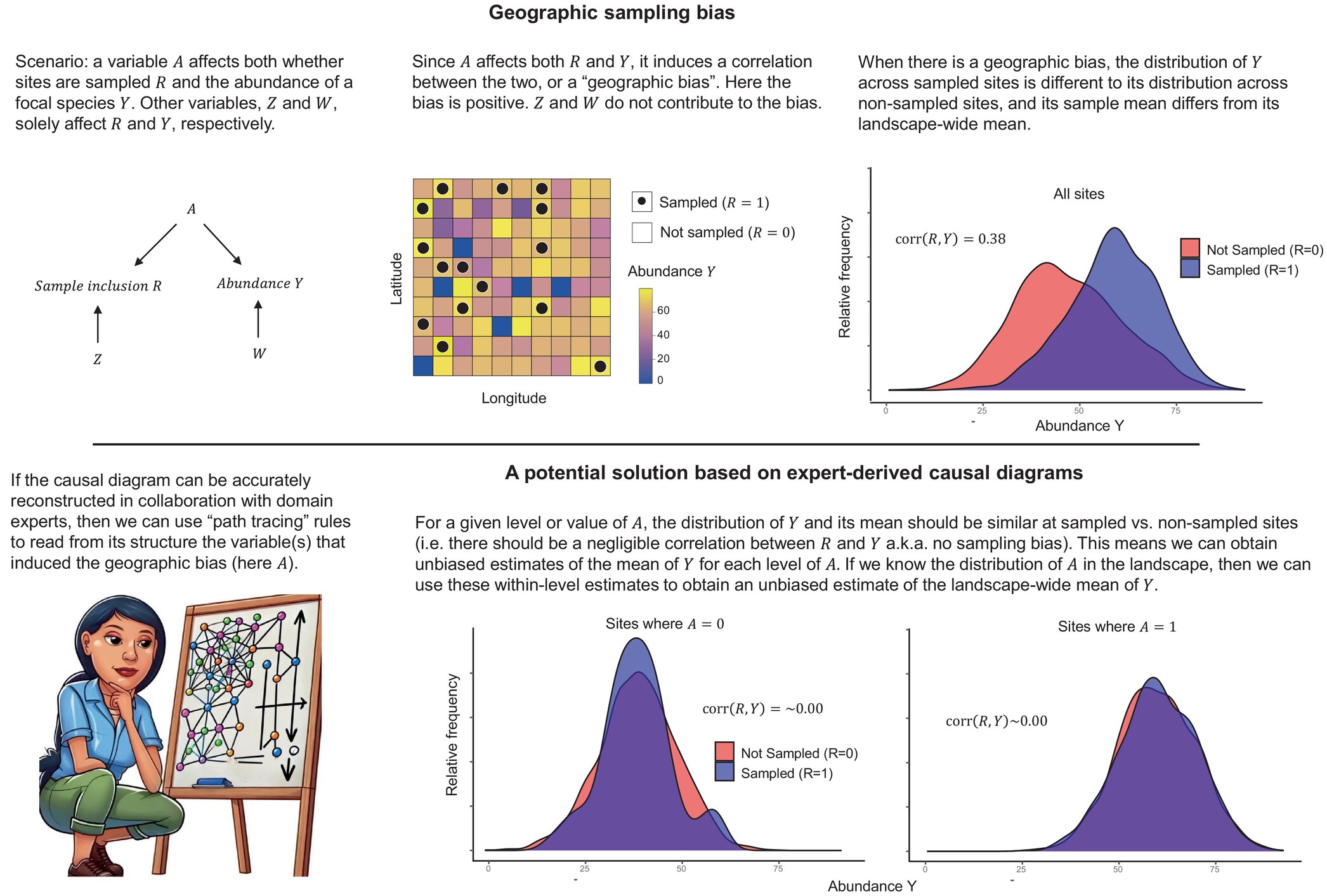
Dans l’échantillonnage de l’enquête, il existe un type spécial de biais appelé biais d’échantillonnage. La définition précise du biais d’échantillonnage a été chicanée par les statisticiens, mais pour moi, il est exprimé de manière très satisfaisante en termes de corrélation. Imaginez que nous sommes intéressés par l’abondance d’une espèce sur un ensemble de sites et que seule une fraction de ces sites a été échantillonnée. La corrélation entre la probabilité d’être incluse dans l’échantillon et l’abondance de l’espèce à travers les sites capture parfaitement le concept de favoritisme en ce qu’elle indique si certaines valeurs d’abondance ont probablement été préférentiellement échantillonnées. En effet, une définition analogue du biais d’échantillonnage, basée sur la corrélation entre si et comment les gens réagissent aux sondages d’opinion, commence à gagner du terrain en sciences politiques (Bailey, 2023).
Un avantage majeur de définir le biais d’échantillonnage comme une corrélation est qu’il devient clair comment atténuer ses effets. Il est assez connu que la corrélation entre deux variables peut être réduite en tenant certaines autres variables constantes (officiellement appelées «conditionnement sur»). Dans l’exemple donné ci-dessus, il existe un biais d’échantillonnage si la probabilité que les sites soient inclus dans l’échantillon sont corrélés avec l’abondance de l’espèce. Mais nous pourrions constater qu’en nous concentrant sur les sites dans les zones protégées, la corrélation disparaît. Dans ce cas, nous avons conditionné à un niveau de statut de surface protégé (à l’intérieur) et, ce faisant, a éliminé le biais d’échantillonnage. La question est de savoir comment identifier les variables qui présentent cette propriété atténuant le biais une fois conditionné (encore une fois, pensez-vous constant).
Une réponse à cette question peut trouver dans une sous-discipline de statistiques connues sous le nom d’inférence causale, où les analystes sont confrontés à un défi similaire. Pour isoler l’effet causal d’une variable sur une autre, des variables qui induisent une corrélation parasites entre les deux doivent être identifiées et conditionnées (la dernière fois: maintenue constante). La façon dont les gens de l’inférence causale s’attaquent à ce problème consiste à construire des «diagrammes causaux» représentant leurs hypothèses sur les liens causaux entre les variables du système. Les variables sont représentées par des «nœuds» et les effets causaux sont désignés à l’aide de flèches. La disposition des flèches et des nœuds peut être traduite en instructions formelles sur les dépendances entre les variables dans le diagramme causal et quelles variables doivent être conditionnées pour les briser.
Maintenant pour la partie intelligente. Si nous incluons la probabilité d’être inclus dans l’échantillon dans notre diagramme causal, nous pouvons déterminer quelles variables doivent être conditionnées pour la rendre indépendante – et donc non corrélée avec – notre variable d’intérêt. Autrement dit, nous pouvons utiliser le diagramme pour identifier les variables sur lesquelles, une fois conditionné, éliminer le biais d’échantillonnage!
Naturellement, il y a une prise. Il est difficile de construire des diagrammes causaux réalistes. Il nécessite une connaissance des causes et des effets de l’inclusion des échantillons et de la variable qui est étudiée (abondance dans l’exemple ci-dessus). Même les causes et les effets indirects qui sont médiés par d’autres variables pourraient s’avérer importants. À mon avis et celle de mes co-auteurs, la meilleure façon de construire des diagrammes de causalité réalistes est de rechercher les commentaires des experts locaux de taxon et d’ensemble de données. Le moyen optimal de s’engager avec les experts et de solliciter et d’assembler leurs commentaires est probablement spécifique au contexte.
Découvrez le papier!
Si vous avez trouvé ce billet de blog intéressant, veuillez consulter notre article dans Moi (Boyd et al., 2025). Le document fait essentiellement deux choses. La première consiste à formaliser les concepts que j’ai introduits ici. La seconde consiste à démontrer comment ces concepts peuvent être traduits dans une méthode opérationnelle, en utilisant des données sur l’abondance de deux espèces de papillons du schéma de surveillance des papillons britanniques à titre d’exemple. Voir la figure ci-dessous pour un aperçu conceptuel.
Abdurahman, S., Atari, M., Karimi-Malekabadi, F., Xue, MJ, Trager, J., PS, PS, Golazian, P., Omran, A., et Dehghani, M. (2024). Périls et opportunités dans l’utilisation de modèles de langues importants dans la recherche psychologique. NEXUS PNAS, 3(7). https://doi.org/10.1093/pnasnexus/pgae245
Bailey, MA (2023). Un nouveau paradigme pour le sondage. Harvard Data Science Review, 5(3). https://doi.org/10.1162/99608f92.9898eedee
Boyd, RJ, Botham, M., Dennis, E., Fox, R., Harrower, C., Middlebrook, I., Roy, DB et Pescott, OL (2025). En utilisant des diagrammes causaux et des modèles de superpopulation pour corriger les biais géographiques dans les données de surveillance de la biodiversité. Méthodes en écologie et en évolution. https://doi.org/10.1111/2041-210x.14492