
Traitement des données d’enquête visuelle avec sampley – Blog des méthodes

Message fourni par Jonathan Syme
Imaginez cette scène idyllique : vous êtes à bord d’un navire de recherche qui avance régulièrement à travers la vaste mer bleue, effectuant des allers-retours le long d’un ensemble de lignes de transect, sa trace étant enregistrée par un GPS. A travers vos jumelles, vous voyez une colonne d’embruns, un dos cambré, un coup de chance qui s’élève bien au-dessus de l’eau, puis disparaît. Vous criez « baleine ! » et votre collègue saisit l’observation – le lieu, l’heure, l’espèce – dans la base de données.
Imaginez maintenant cette scène pas si idyllique : vous êtes dans un bureau et vous vous familiarisez progressivement avec le vaste ensemble de données qui vous a été fourni. La trace du navire de recherche est désormais une ligne qui zigzague sur votre écran, l’observation de la baleine est désormais un point. Votre tâche consiste à analyser les traces et les observations, les lignes et les points, en construisant un modèle. Mais le modèle nécessite en entrée un ensemble d’échantillons, chacun représentant un endroit dans le temps et dans l’espace où une baleine a été ou non détectée. Ainsi, avant même de passer à la modélisation, vous avez une tâche à accomplir : transformer les traces et les observations en échantillons.
Bien que j’aie eu la chance de vivre cette scène idyllique, malheureusement pour vous, cher lecteur, cet article concerne la scène pas si idyllique, donc il n’y aura plus de paroles lyriques sur les baleines, ou les dauphins sautant acrobatiquement dans la vague d’étrave, ou les puffins glissant sans effort sur une eau vitreuse… Bref, au point. Cet article concerne sampley, un package Python que nous avons développé spécifiquement pour cette tâche pas si idyllique : traiter les données d’enquête visuelle, telles que les traces et les observations, en échantillons pouvant être intégrés dans un modèle écologique.

Les nombreuses façons de traiter les données d’enquête visuelle
Après une brève revue de la littérature, il est devenu clair qu’il existe de nombreuses façons de traiter les traces et les observations en échantillons. Vous pouvez diviser l’océan en cellules de grille, découper les traces en segments ou générer des points qui représentent les présences et les absences. Mais il y avait plus que cela : les cellules peuvent être rectangulaires ou hexagonales, petites ou grandes ; les pistes peuvent être segmentées avec différents degrés de complexité et de standardisation ; et les points d’absence peuvent être générés de différentes manières selon les études.
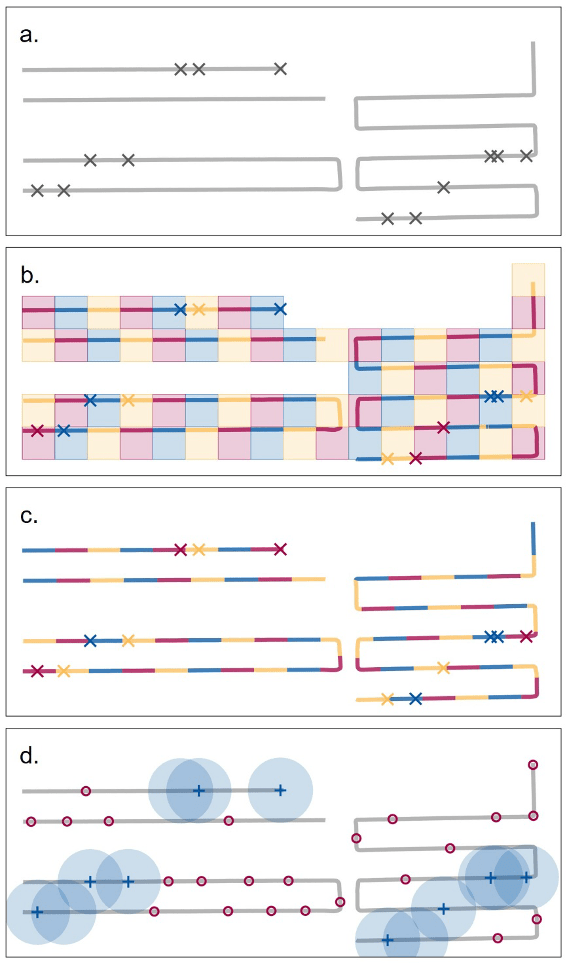
Bien que de nombreux articles décrivent leurs méthodes de traitement, très peu, voire aucun, donnent des détails spécifiques sur la façon dont le traitement a été effectué. Quel logiciel a été utilisé ? Quels algorithmes ? La plupart des chercheurs ont leurs propres scripts personnalisés qu’ils ont développés et qu’ils ajustent pour chaque nouveau projet, tout comme je l’avais fait pendant mon doctorat et mes superviseurs l’avaient fait à plusieurs reprises auparavant. Et, bien que ces scripts personnalisés fonctionnent, ils posent quelques problèmes. Il y a un manque de reproductibilité, étant donné que les scénarios sont généralement inédits, ainsi qu’une charge considérable en termes de temps et de savoir-faire nécessaires à leur élaboration. Ce fardeau n’est qu’alourdi si vous souhaitez tester et comparer plusieurs méthodes, mais, peut-être attirés par le défi, c’est ce que nous avons décidé de faire.
Développer Sampley pour en faire un outil largement applicable
Quelque temps plus tard, mon superviseur postdoctoral Dan, dans sa manière désinvolte et désinvolte de suggérer des choses auxquelles il a beaucoup réfléchi, a dit « hé, vous savez, nous devrions transformer cela en un package ». À ce stade, nous disposions d’un code permettant de traiter les traces et les observations de diverses manières, ce qui reste au cœur des fonctionnalités de sampley, mais il a été adapté à notre ensemble de données. Au fil du temps, et après consultation d’autres chercheurs (un grand merci à eux pour leur contribution !), nous avons élargi l’applicabilité afin qu’elle soit désormais adaptée à une variété de types et de formats de données.
De plus, dans un souci de convivialité, le package ne contient qu’un petit nombre de fonctions organisées en trois étapes avec une série d’étapes simples. Enfin, comme l’idée de Python peut susciter un inconfort chez les nombreux écologistes fidèles à R, nous avons inclus des conseils détaillés et de nombreux exemples afin que la courbe d’apprentissage pour ceux qui ne sont pas familiers avec Python soit plutôt une pente douce.
Utilisations de l’échantillon
Nous pensons que sampley résoudra les problèmes rencontrés par les chercheurs lors du traitement des données d’enquête visuelle en échantillons : il permettra d’économiser du temps et des efforts, de faciliter l’essai de plusieurs méthodes de traitement des données et d’améliorer la reproductibilité. De plus, pour l’ordinateur, les lignes ne sont que des lignes et les points ne sont que des points. Ainsi, même si, dans notre travail original, ils représentent des traces de navires et des observations de baleines, pour d’autres, ils pourraient représenter à peu près tout ce qui peut prendre la forme d’une ligne ou d’un point. Par exemple, les lignes pourraient être les chemins qu’un observateur suit et les points les oiseaux qu’il voit.
Et donc, si vous vous trouvez dans votre propre version de la scène pas si idyllique, nous vous encourageons à visiter la page du projet PyPI (https://pypi.org/project/sampley/) où vous trouverez des liens vers le manuel d’utilisation et de nombreux exemples, ainsi que le package lui-même et, espérons-le, sampley vous soulagera d’une partie du fardeau et vous permettra de revenir à votre scène idyllique, quelle qu’elle soit.
Lire l’article complet ici.