
Modélisation des enquêtes d’identification d’image avec des erreurs de classification – Blog de méthodes

Post fourni par Jon Barry
Nous sommes un groupe composé de statisticiens, d’écologues et d’un informaticien. En 2021, lorsque ce travail a commencé, nous étions tous employés au Center for Environment, Fisheries and Aquacultural Science (CEFAS) à Lowestoft, au Royaume-Uni, Robert, notre informaticien, a «sauté le navire» (sans jeu de mots) à la Institut Alan Turing.
Nous étions conscients que la reconnaissance d’image de l’IA était largement utilisée dans de nombreux domaines de la science – comme la médecine, la télédétection par satellite, les véhicules autonomes, la reconnaissance du visage et la robotique. Et d’autres scientifiques de l’ACEFA avaient utilisé l’identification d’image pour la cartographie des fonds marins, le changement de rivage et l’identification des poissons. Tout le monde le faisait, alors pourquoi pas nous?
Étant donné que nous étions encore aux prises avec la pandémie, il y avait beaucoup de temps pour réfléchir. Et parce que je savais que ces techniques de reconnaissance d’image n’étaient pas précises à 100%, j’ai été attiré par l’expérience de pensée suivante.
Notre expérience de pensée
Imaginez que vous essayez de faire la distinction entre trois espèces de plancton. En outre, imaginez que votre algorithme d’IA rapporte le nombre suivant: 4 des espèces A, 3 des espèces B et 5 des espèces C. Ces dénombrements se reflètent dans le nombre d’individus dans chaque rangée du diagramme ci-dessous. Mais, comme vous pouvez le voir, il y a des erreurs. Par exemple, la première rangée montre que les 4 espèces «A» sont vraiment 3 espèces A et 1 espèce B. De même, la deuxième rangée montre que les 3 espèces «B» sont en fait 2 espèces B et 1 espèce A. et, si Nous regardons les 12 images ci-dessous, les comptes corrects sont: 5 des espèces A, 4 des espèces B et 3 des espèces C – toutes différentes de ce que l’IA nous a dit!

Toute cette pensée mène à la question évidente: «Existe-t-il un moyen de remédier aux erreurs de l’IA?» La clé de la réponse est que si nous comprenons comment Les erreurs se produisent, alors nous devrions être en mesure de démêler les choses pour trouver quelque chose de plus proche de la vérité. Heureusement, il existe un outil pour comprendre le «comment» des erreurs: la matrice de confusion.
La matrice de confusion
Le concept d’une matrice de confusion est au cœur de notre travail. Notre modèle utilise des versions observées et latentes (ne demandez pas) de la matrice de confusion, mais pour rester simple, permettez-moi d’essayer d’expliquer la version observée.
À titre d’exemple, revenons à quelques étapes, jusqu’à lorsque l’algorithme de reconnaissance du plancton AI a été formé (plus de détails ci-dessous). En bref, cela a été fait en utilisant environ 57 000 images où nous connaissions la «bonne réponse». Une fois la formation terminée, nous avons utilisé des images fraîches (non utilisées dans la formation) pour vérifier dehors Comment notre algorithme se comportait – c’est-à-dire pour calculer la matrice de confusion.
La matrice de confusion résume comment les images d’une catégorie connue (pour nous, copépodes, détritus et non cocopepodes) sont prédites par le classificateur AI. Pour l’exemple ci-dessous, dans la rangée supérieure, 909 (ou 95,2%) sur 955 de vrais copépodes ont été correctement identifiés par le classificateur AI comme copépodes; 7 ont été identifiés à tort comme des détritus et 39 comme des non-copepodes. Dans la deuxième rangée, 71 éléments de détritus ont été faussement identifiés comme des copépodes, 3977 correctement identifiés et 74 incorrectement étiquetés comme non cocopepodes. Mettez les trois rangées ensemble et vous obtenez une matrice de confusion comme celle que nous avons utilisée dans notre article:
| Copépodes | Détritus | Non-copepods | |
| Copépodes | 909 | 7 | 39 |
| Détritus | 71 | 3977 | 74 |
| Non-copepods | 42 | 16 | 547 |
Comment notre travail s’est développé
Nous avons commencé à l’origine nos travaux en dérivant des résultats simples (fréquentistes) pour le moment où le nombre d’espèces avait une distribution de Poisson (ce qui pourrait être vrai si le plancton était distribué au hasard dans l’espace). Cependant, nous avons vite réalisé que si nous voulions être en mesure d’analyser un éventail beaucoup plus riche de modèles, nous avions besoin d’un cadre bayésien. Ce que nous avons finalement inventé nous permet, par exemple, d’analyser les situations dans lesquelles les vrais comptes ont une distribution binomiale négative (par exemple où les espèces sont regroupées), où il y a un mélange de Poisson et de distributions binomiales négatives entre les espèces et où les espèces comptent les espèces Avoir une distribution de Poisson gonflée zéro (où le nombre de zéros et les dénombrements non nuls sont modélisés en parties distinctes).
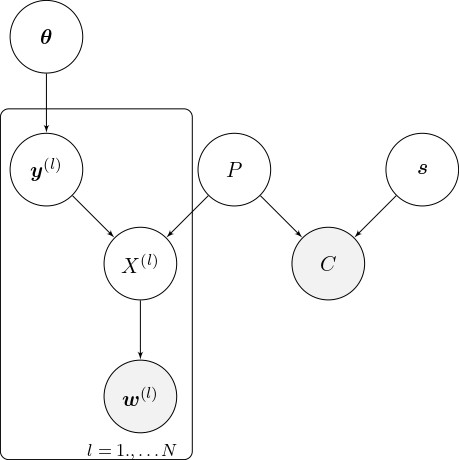
Notre cadre bayésien peut être bien résumé par ce qu’on appelle un graphique acyclique dirigé (DAG pour faire court). Vous trouverez ci-dessous la figure 1 de notre article. Vous devrez lire le papier pour comprendre pleinement ce qui se passe mais, en bref, ce graphique montre le lien entre ce que nous observons réellement (cercle ombré. et matrice de confusion
) et le reste des composants du modèle. Nous sommes principalement intéressés par les paramètres sous-jacents (
) qui génèrent les vrais comptes. Ceux-ci pourraient être attendus des niveaux d’une espèce, par exemple. Notre algorithme génère des distributions pour ces paramètres en fonction de notre modèle et conditionnel sur les comptes observés et la matrice de confusion.
Plus de trucs sur le plancton
L’algorithme du classificateur AI pour le plancton anime la plupart des travaux de notre article. En 2021, l’Institut Alan Turing a organisé un groupe d’étude de données pour examiner le problème de la classification automatisée du plancton. L’imageur du plancton (voir l’image ci-dessous) a été utilisé pour générer un ensemble de données d’images étiquetées composées de copépodes (10 275), de non-cocopepodes (6 716) et de détritus (40 000). (Notez que les copépodes sont un groupe de zooplancton qui mérite une attention particulière: ce sont souvent les taxons dominants dans les échantillons collectés.) À partir de ces images, l’algorithme d’IA utilisé dans cet article a été développé.

{kind=link}

Où ensuite?
Notre méthode est largement applicable dans de nombreux domaines où des erreurs de classification se produisent. J’ai expliqué les concepts en termes de classificateur d’IA. Cependant, le classificateur n’a pas à utiliser l’IA ou même les ordinateurs. Par exemple, n’oubliez pas le test d’écoulement latéral de la pandémie covide? Il a classé les échantillons de salive comme étant covide positifs ou négatifs. Et, comme l’IA, il se trompe parfois.
La vue d’ensemble pour nous au CEFAS est que nous voulons utiliser la classification des images AI pour effectuer une surveillance environnementale – nous voulons donc que les mathématiques soient correctes.
La tâche suivante pour les statisticiens de cet article est de modifier notre approche afin qu’elle puisse être utilisée pour l’identification des litière de plage à partir d’images fournies par les drones. Il y aura beaucoup plus de catégories (jusqu’à 80) que pour le plancton – ce sera donc un défi!
Lire l’article complet ici!
Post édité par Swingwe Kanyile