
Aborder les biais d’observation dans les approches basées sur les données de la prédiction des risques zoonotiques – Blog de méthodes

Post fourni par Andrea Tonelli
Au cours des cinq dernières décennies, plus de la moitié des maladies infectieuses émergentes chez l’homme sont originaires des animaux, avec Les agents pathogènes zoonotiques constituant une menace croissante pour la santé mondiale. Changements dans l’utilisation des terres, le changement climatique, l’utilisation directe de la faune et la perte de biodiversité influencent toutes l’exposition humaine aux agents pathogènes des animaux sauvages, façonnant la probabilité de Événements de débordement zoonotique. Dans le sillage de Covid-19, la compréhension des interactions hôte-pathogène et les mécanismes stimulant les retombées des agents pathogènes sont devenus l’un des défis déterminants de notre temps.
Compte tenu de l’incertitude concernant la distribution des agents pathogènes des animaux dans le monde, un intérêt croissant a été consacré à Développer des approches innovantes et axées sur les données Cela pourrait compléter les méthodes de surveillance traditionnelles pour la prévention des retombées zoonotiques et compenser certaines des lacunes cruciales de connaissances. L’apprentissage automatique et la modélisation prédictive ont gagné du terrain pour identifier la gamme d’hôtes des agents pathogènes – c’est-à-dire le spectre de différentes espèces qu’un agent pathogène peut infecter – pour identifier les espèces hôtes potentielles et les cibles identifiées pour la surveillance des risques zoonotiques.
 Figure 1 Les scientifiques capturant les renards volants au Cameroun. Des activités de surveillance périodiques sont menées dans des populations de chauves-souris résidant près des établissements humains où les gens pourraient être exposés à des débordements viraux. Crédits d’image: © Jean-François Lagrot
Figure 1 Les scientifiques capturant les renards volants au Cameroun. Des activités de surveillance périodiques sont menées dans des populations de chauves-souris résidant près des établissements humains où les gens pourraient être exposés à des débordements viraux. Crédits d’image: © Jean-François LagrotCes modèles apprennent des caractéristiques biologiques et écologiques des hôtes connus, et s’ils ne sont pas utilisés avec soin, ils sont enclins à reproduire biais dans les associations d’hôte-pathogène. En effet, les efforts de recherche se sont historiquement concentrés sur des taxons animaux et pathogènes particuliers, conduisant à une compréhension incomplète et biaisée de la distribution des agents pathogènes entre les espèces hôtes. Par exemple, La découverte de virus associés aux chauves-souris a connu une tendance à la hausse sans précédent après l’émergence du SARS-CoV en 2002. Les chauves-souris sont connues pour accueillir la plus grande diversité de virus parmi les mammifères, cependant, il est difficile de découpler l’effet de l’effort de recherche de celui des caractéristiques biologiques et écologiques qui peuvent rendre les chauves-souris plus sujets à l’hébergement d’une plus grande diversité de virus.
Dans notre article, nous avons fait un pas vers la comptabilité de biais bien connus qui affectent l’échantillonnage viral dans les modèles d’apprentissage automatique pour la prédiction de l’hôte. Premièrement, nous avons classé des espèces positives dans les hôtes à faible preuve et à haute preuve, où ces derniers sont des hôtes pour lesquels des études d’observation suggèrent une capacité potentielle de l’espèce à maintenir l’agent pathogène dans l’environnement. Notre étude de cas sur les bétacoronavirus comprenait des microbats, des chauves-souris, des insectivores et des rongeurs comme hôtes à haute preuve, qui ont été traités dans l’analyse afin de donner une contribution plus élevée aux prédictions du modèle, par rapport aux hôtes à faible preuve. De plus, les données sur les associations de pathogène hôte ne sont généralement pas avec des négatifs (c’est-à-dire des espèces qui ne peuvent pas être infectées par un pathogène donné), nous avons donc introduit le concept de pseudo-négatifs. Nous avons choisi des espèces pseudo-négatives parmi celles qui étaient susceptibles d’avoir subi un échantillonnage virologique mais n’ont pas d’associations documentées avec le virus cible, tirant parti des modèles de proximité taxonomique et de chevauchement géographique avec les espèces échantillonnées. Enfin, afin d’estimer la précision attendue de notre cadre, nous avons testé notre modèle sur de nouveaux positifs – c’est-à-dire de vraies espèces positives qui ont été échantillonnées après la publication de le réseau hôte-virus que nous avons analyséet donc n’est pas entré dans la formation du modèle. Pour cet ensemble indépendant de nouvelles espèces positives, la probabilité moyenne prédite d’être un hôte était plus de 35% plus élevée que celle des hôtes encore inconnus, ce qui suggère que notre cadre de modélisation est en effet capable d’identifier correctement les hôtes actuellement échantillonnés.
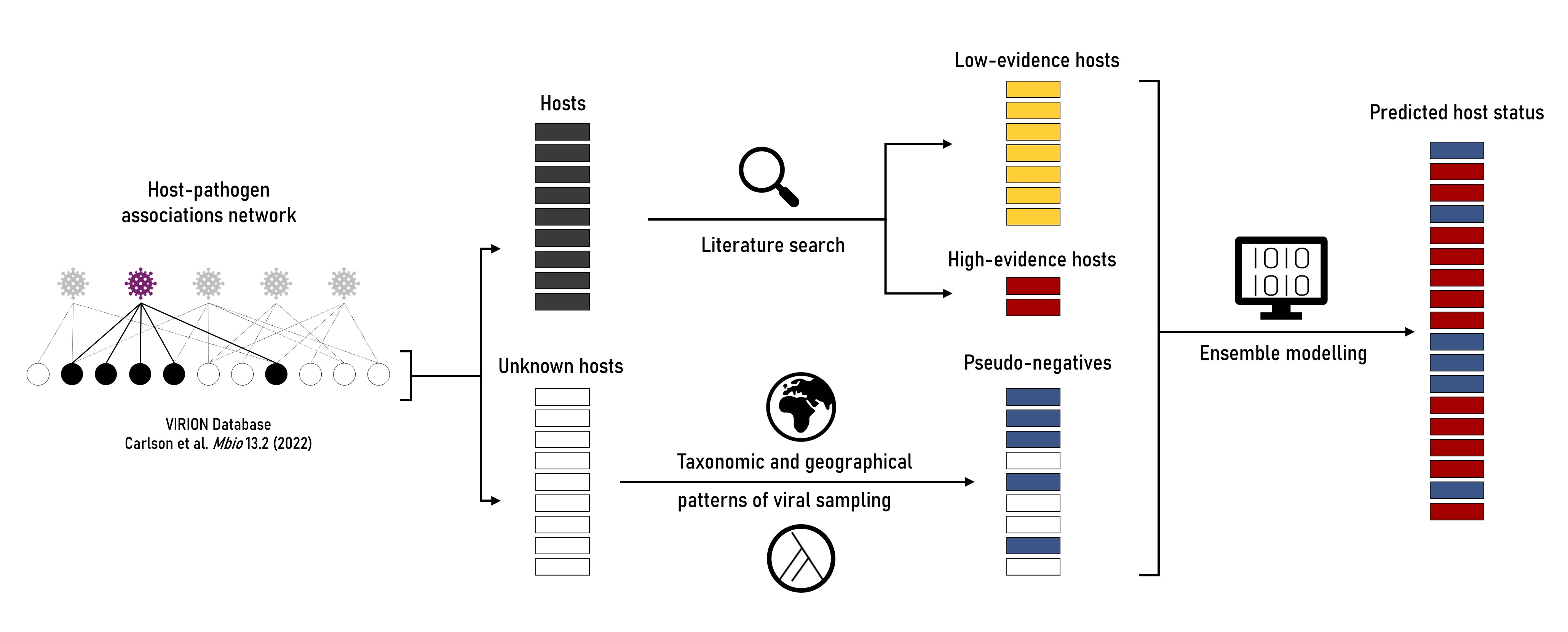
Étapes futures
Alors que les outils analytiques continuent d’évoluer et que les données de meilleure qualité deviennent de plus en plus disponibles, l’intégration de l’apprentissage automatique dans l’évaluation des risques zoonotiques a le potentiel de bénéficier aux efforts de surveillance de la maladie, soutenant potentiellement des réponses plus efficaces et proactives aux menaces infectieuses émergentes. Avec les bases de notre cadre en baisse, nous travaillons actuellement à l’application de nos méthodes à une plus grande variété de virus avec un potentiel zoonotique qui peut constituer une menace pour la santé publique. Si vous êtes passionné par la macroécologie des maladies infectieuses et les façons d’anticiper les risques zoonotiques, ou d’avoir des pensées sur notre article et nos étapes futures potentielles, j’aimerais avoir de vos nouvelles! Vous pouvez contacter moi à ndrtonelli@gmail.com.
Lire l’article complet ici.