



Message fourni par Brooke Bond (Gibbons)

Les écologistes rêvent souvent de grands ensembles de données. La combinaison d’observations issues de plusieurs études dans l’espace et dans le temps pourrait révéler des tendances qui seraient autrement impossibles à détecter. Mais quiconque a tenté de fusionner des ensembles de données provenant de différentes sources sait que la réalité est souvent moins glamour.
Mon premier travail consistait à synthétiser des ensembles de données Baited Remote Underwater Video (BRUV) provenant de toute l’Australie. Les systèmes BRUV utilisent des caméras sous-marines et des appâts pour enregistrer les poissons et leur habitat, permettant ainsi aux chercheurs d’identifier les espèces et de mesurer la taille du corps directement à partir de séquences vidéo. Au cours des deux dernières décennies, cette approche est devenue largement utilisée car elle est rentable, produit un enregistrement permanent et permet l’identification des espèces au bureau.
Début 2018, des chercheurs australiens m’ont remis des ensembles de données et m’ont demandé de les combiner dans un format ordonné avant un atelier national BRUV. Au début, la tâche semblait simple ; combinez simplement le tout pour que tout le monde puisse commencer à analyser les données et à rédiger des articles.
Ensuite, j’ai ouvert les fichiers.
La réalité de la combinaison d’ensembles de données
La synthèse a finalement combiné 19 939 déploiements BRUV collectés par 32 chercheurs dans 12 institutions (Harvey et al. 2021). L’ensemble de données final comprenait plus de 1,16 million d’observations de poissons et 373 000 mesures de taille corporelle. Chaque groupe avait suivi des méthodes d’enquête globalement similaires, mais la manière dont les données étaient stockées, annotées, formatées et exportées variait. Certains ensembles de données utilisaient différents noms d’espèces, variations orthographiques ou taxonomie héritée, soulignant les défis et les opportunités liés à l’harmonisation des enregistrements collectés au travers de plusieurs programmes et décennies. De temps en temps, nous tombions sur une erreur de saisie évidente qui nous faisait rire et contactions l’un des collaborateurs pour la corriger. Ces expériences ont renforcé la valeur de protocoles clairs, de contrôle qualité et de communication lors du regroupement des observations recueillies par de nombreuses équipes différentes.
Pour vous aider à détecter, signaler et communiquer les problèmes courants, nous avons commencé à écrire du code. Au fur et à mesure que nous rencontrions de nouveaux problèmes, le code devenait progressivement plus complexe.


Du code à un outil communautaire
Ce qui a commencé comme une solution pour un atelier s’est lentement transformé en un ensemble plus large d’outils de contrôle qualité pour l’ensemble de la communauté. Bien que les chercheurs aient suivi les mêmes manuels de terrain, la combinaison des ensembles de données a révélé de nombreux problèmes de données récurrents qui étaient auparavant passés inaperçus.
Puis est arrivée la pandémie de COVID-19.
Le travail sur le terrain étant interrompu, nous avons soudainement eu le temps de revoir le code et de réfléchir à la manière dont il pourrait devenir utile au-delà de notre propre projet et accessible aux personnes sans compétences en codage. Nous avons donc transformé le flux de travail en une application Web.
C’est devenu CheckEM, abréviation de Check EventMeasure, un logiciel d’annotation couramment utilisé pour les enquêtes stéréo-vidéo. L’objectif n’était pas de « corriger » automatiquement les données, mais d’aider les chercheurs à identifier facilement les problèmes potentiels et à corriger leurs annotations avant le début de l’analyse.
Aujourd’hui, CheckEM est disponible à la fois sous forme de application Web interactive et comme un paquet R open sourcepermettant aux utilisateurs d’intégrer les contrôles directement dans leurs flux de travail.
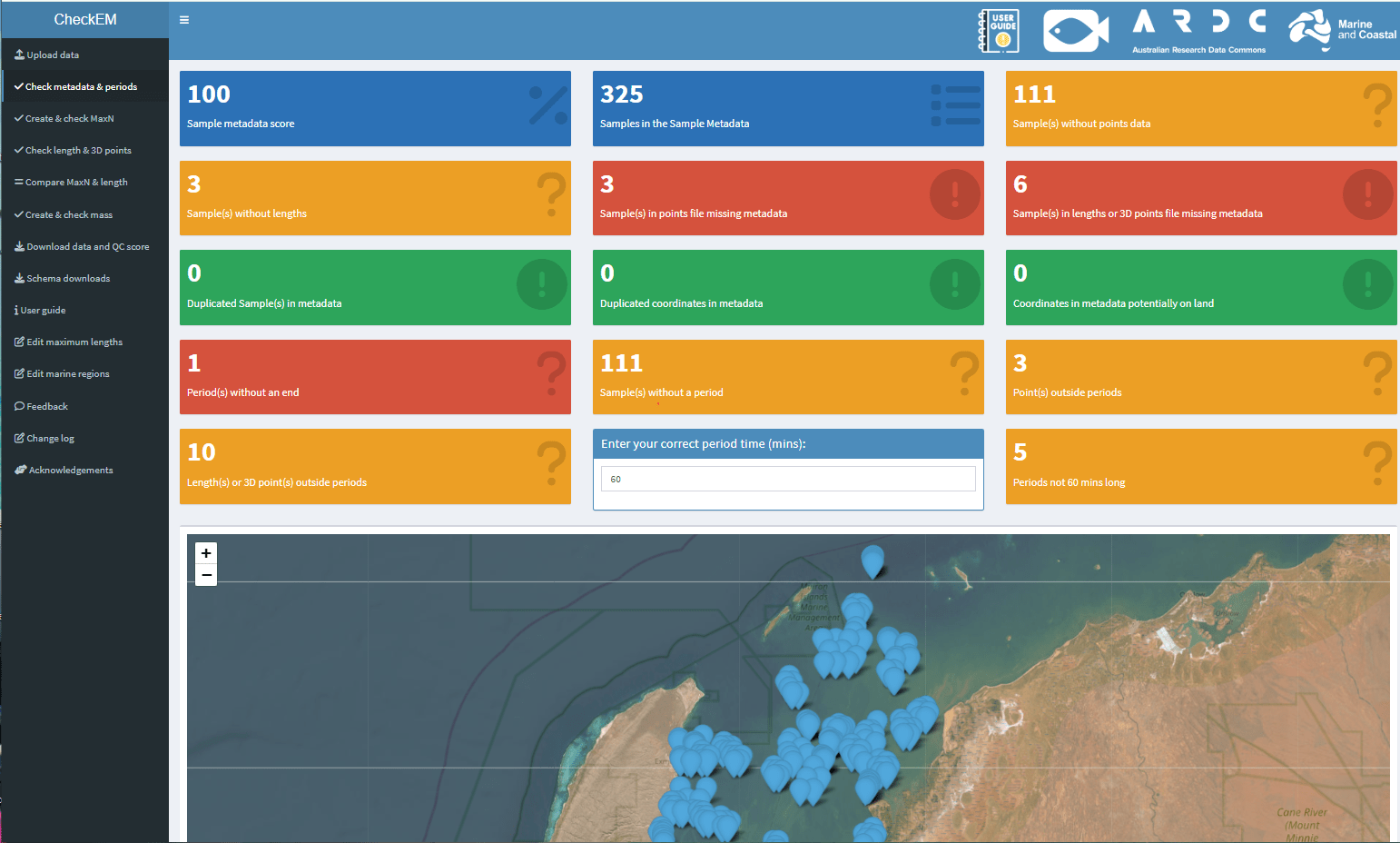
Ce que CheckEM vérifie
CheckEM compare les données d’enquête téléchargées avec les informations de référence taxonomiques et biologiques.
Par exemple, il peut :
- détecter les noms scientifiques périmés ou mal orthographiés
- espèces emblématiques observées en dehors de leur aire de répartition connue
- identifier les mesures de poissons plus grandes que la taille maximale enregistrée
- mettre en évidence les métadonnées manquantes ou incohérentes
- générer des rapports d’erreurs et des ensembles de données récapitulatifs
Il est important de noter que CheckEM ne modifie pas automatiquement les données. Au lieu de cela, il signale les entrées suspectes afin que les chercheurs puissent revenir aux annotations ou images originales et les vérifier. Parfois, ces observations signalées sont en réalité des erreurs. Mais parfois, ils révèlent quelque chose d’intéressant, comme une véritable extension de l’aire de répartition ou un individu inhabituellement grand.
Pourquoi la qualité des données est importante
La recherche écologique moderne s’appuie de plus en plus sur de vastes ensembles de données synthétisées pour comprendre les changements environnementaux à l’échelle régionale ou mondiale.
Même de petites erreurs peuvent influencer les résultats. Par exemple, une mesure incorrecte de la longueur du corps peut affecter considérablement les estimations de la biomasse. Garantir la qualité des données avant l’analyse est essentiel pour produire des conclusions fiables. Les valeurs aberrantes réellement validées sont souvent à l’origine de nouvelles idées et hypothèses. Mais avant de nous lancer dans ces nouvelles voies de recherche, nous devons nous assurer que les données sont réelles et non une faute de frappe.
CheckEM aide les chercheurs à passer moins de temps à vérifier manuellement les feuilles de calcul et plus de temps à analyser leurs données.
Une collaboration grandissante
La première synthèse BRUV qui a inspiré CheckEM a rassemblé des milliers de déploiements à travers l’Australie. Depuis, la collaboration au sein de la communauté BRUV n’a cessé de se développer.
L’atelier BRUV a été répété en 2024, réunissant davantage d’organisations et de déploiements tout en intégrant bon nombre des leçons apprises lors de l’effort initial.
La synthèse élargie compte désormais 29 505 échantillons BRUV avec 1,77 million de poissons individuels, près de 2 000 espèces de poissons, plus de 580 000 mesures de longueur et plus de 20 covariables environnementales et socio-économiques sont fournies pour chaque échantillon. Ce qui en fait l’un des plus grands ensembles de données nationales intégrées sur l’écologie marine jamais créés.
À mesure que les ensembles de données deviennent plus volumineux et plus interconnectés, les outils permettant de garantir leur qualité deviennent de plus en plus importants.

Regarder vers l’avenir
CheckEM a commencé comme une réponse pratique à un problème bien réel : des ensembles de données collaboratifs difficiles à combiner. Ce qui a commencé comme une poignée de code écrit sous la pression du temps est devenu une boîte à outils open source utilisée par les chercheurs du monde entier.
En rendant le contrôle qualité plus rapide et plus accessible, nous espérons que CheckEM aidera les chercheurs à passer moins de temps à nettoyer les données et plus de temps à les utiliser pour comprendre, gérer et protéger les écosystèmes marins.
CheckEM a été soutenu par le gouvernement australien dans le cadre du programme national des sciences de l’environnement Hub marin et côtier et l’Australian Research Data Commons (ARDC), qui est financé par le gouvernement australien dans le cadre de la National Collaborative Research Infrastructure Strategy (NCRIS) à travers le Partenariat pour les données sur les poissons et les requins.
Pour en savoir plus sur CheckEM et comment il peut être utilisé pour les ensembles de données d’enquête sur les poissons, lisez notre papier complet dans Méthodes en écologie et évolution.